
Adam Kaczmarek

Nate Meyer

Phil Brockman
Jul 21, 2025
The Good Problems
Most engineering content focuses on getting from zero to one: how to ship fast, validate ideas, and build something people want.
But there's a gap in the discourse around what happens next: the "good problems" that emerge when your startup actually works and starts gaining real adoption.
As Loops scaled, we had the opportunity to rearchitect our infrastructure and make refinements that helped us maintain the uptime our users had come to expect.
While Vercel, Supabase, and various queue services served us incredibly well in our early days, and we would not be here today without them, we needed to rethink our stack.
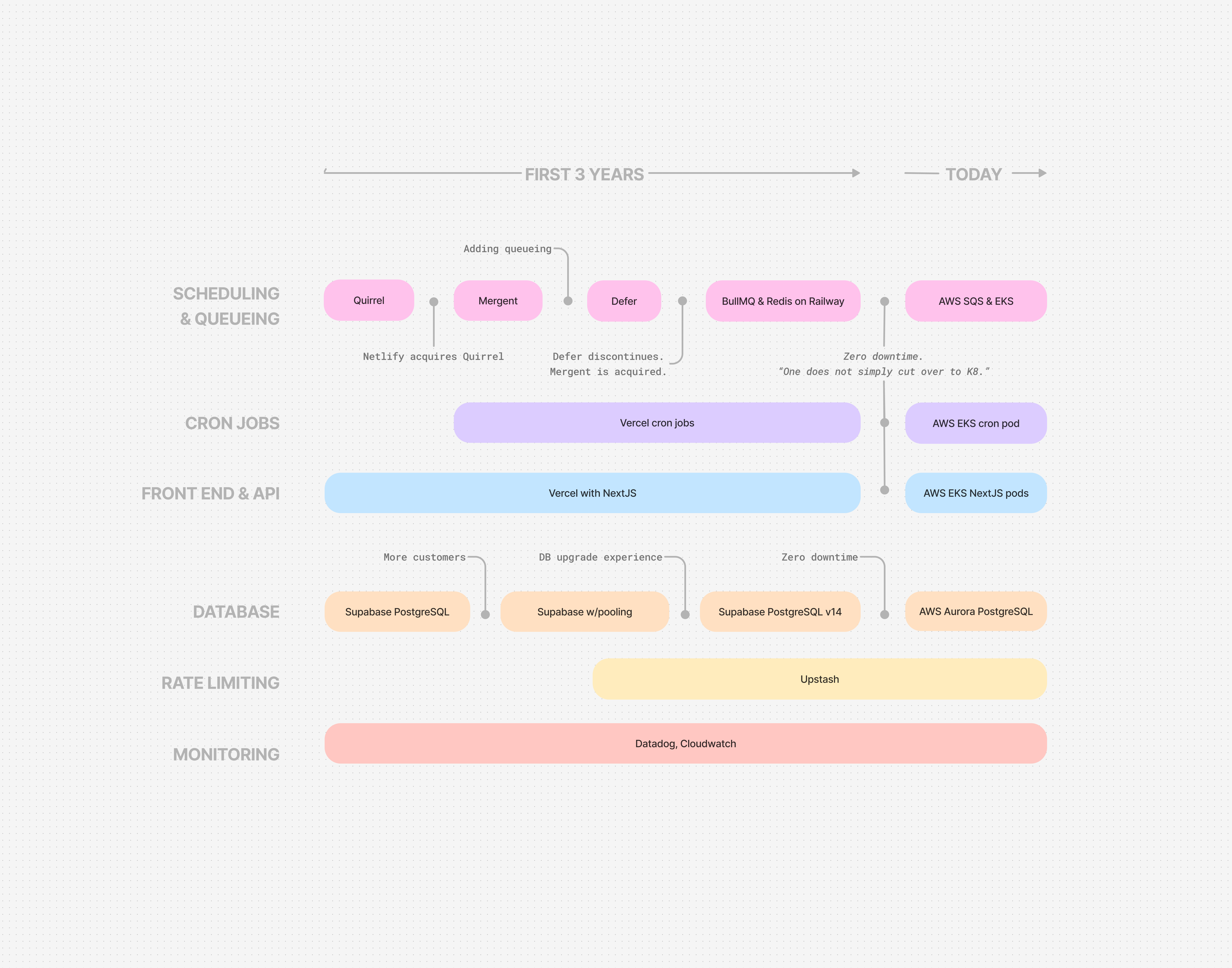
This is the story of our infrastructure evolution at Loops.
The Serverless Compromise
Back in 2022, NextJS felt like the obvious choice: it had a thriving ecosystem, momentum, and the promise of being a "full-stack framework." Furthermore, Vercel made deployment of NextJS trivial.
Quickly we found that Vercel’s cron jobs were only able to hit public endpoints, making us rely on security through obscurity. Even on enterprise tiers, our functions’ maximum duration was capped to 15 minutes.
An entire industry of startups spawned to solve these problems.
We went through Quirrel (RIP), then Mergent (RIP), and briefly tried Defer (RIP). Each worked well until they didn't: Scaling issues, limited monitoring, and the anxiety of depending on black box services during outages.
Eventually, for queue management, we turned to Railway (running BullMQ and Redis).
Note: Vercel has since released features like Vercel Queues that address some of the background task limitations we experienced. The ecosystem continues to evolve rapidly.
The Database Reality Check
With Supabase, we were able to spin up a managed Postgres service and a connection pooler before our ramen cooled off.
Yet it nagged at our team that there was no way to automatically fail over should something happen to our primary db. At the time, without superuser access, performing limited-downtime PostgreSQL version upgrades was extremely challenging.
Accessing the database over the public internet wasn’t ideal either from a security or performance standpoint.
The Breaking Point
Despite the promise of “serverless”, we found ourselves twisted in knots to keep deployments, migrations, and monitoring in sync across our sprawling infrastructure. Our "simple" architecture had become a Rube Goldberg machine that was starting to impact customer experience and our ability ship features as fast as we wanted to.
We'd reached the point where the time saved by using managed services was instead being consumed managing the services themselves. We were a team of scrappy product engineers without a lot of experience building infrastructure, but we knew things needed to change.
It was about this time we brought on a couple folks with platform engineering experience.
Embracing Boring Infrastructure
Over the course of about six months, we planned and executed a migration from our various SaaS providers to our new, cozy Kubernetes and Aurora Postgres clusters. We did this gradually, taking increasingly large bites as we became more comfortable with where things were headed.
We started with a high level doc that laid out the details for which tools, services, and the a rough migration plan for cutting over. Most notably we leaned on Kubernetes (EKS), Aurora, and SQS. These relatively boring choices gave us:
Predictable costs that scale with usage, not vendor pricing tiers
Direct control over performance characteristics
Operational transparency with CloudWatch and direct system access
Changed vendor risk by consolidating to a single, stable provider
Performance improvements by way of moving our database and apps into the same AWS VPC
Continuing to be boring, we chose Terraform to codify our new AWS resources. In short order we had a new VPC and EKS cluster ready to go.
From there, we started with some of our smaller apps, building container images, writing Helm charts, and working out a deployment pipeline. Taking a metered approach enabled us to move workloads into this new environment gradually, minimizing risk, and gaining confidence as we progressed.
We continued and consolidated our background job processing from Railway and BullMQ to SQS and prepared to move our main app from Vercel to Kubernetes.
Cutting Over the Loops App
Once we had our main app up and running in Kubernetes but not yet “live”, we started discussing what the cutover would look like. It was difficult to understand what kind of compute resources we’d need or generally whether our Kubernetes cluster was ready for the load.
We’ve been happily using Cloudflare for DNS, specifically allowing them to proxy DNS requests. We took a swing on a Cloudflare Worker that would send a percentage of requests to AWS instead of Vercel. We were pleasantly surprised to find that this worked relatively well.
Over the course of a couple weeks we experimented with increasing the percentage of traffic routed to AWS. This uncovered several bugs and minor configuration issues in the new environment, such as missing environment variables or incomplete IAM permissions, which were ironed out before the cutover.
Once we felt comfortable with the state of things, we updated the worker routing to send 100% of requests to AWS. We let this run for a couple days, then simply updated our DNS to point directly at our AWS load balancer and took the Cloudflare Worker out of the traffic path.
As an additional safety measure, we continued deploying to Vercel for a period of time afterwards just in case we found something show-stopping and needed to rollback.
Cutting Over the Database
With the compute migration behind us, we turned our attention to the database. We’d already settled on Aurora Postgres, so we whipped up some Terraform and deployed a new Multi-AZ cluster. Our goal was to transition between databases with minimal or no downtime. After some research this is approximately the process we used to sync the data:
Dump the schema from Supabase.
Take the indexes out of the schema dump, and apply the schema to the Aurora.
We configured logical replication for each table. We did this incrementally, paying careful attention to the size of the WAL on the Supabase instance.
Once all tables were successfully replicating, we extracted all indexes from the original schema dump and applied them all.
It’s possible that we could have made this simpler with AWS’s Database Migration Service, but we were a bit leery to introduce more moving parts.
With the replication doing its thing, we scheduled a maintenance window to do a final cutover. The technically correct approach may have been to take the apps down, or otherwise stop writes to Supabase, but if we’re down our customers can’t send email and that’s not an acceptable state for us.
We opted to simply update our database connection string on the AWS app and point it to Aurora. This had potential for producing conflicts that may have broken replication, but we believed the risk to be small.
We made the change and everything just worked! 🎊
A few hours later, we did run into a few minor replication issues due to accepting writes on both databases. The fixes were straightforward.
We let this bake for a day or so and when we saw there was effectively no traffic to Vercel or Supabase, we disabled replication.
Despite the nerves we had, it was a shockingly smooth process.
The Reality of Migration
Things will break. You'll discover dependencies you forgot about. Database migrations are genuinely hard (shoutout to Theo for covering this extensively).
Plan for downtime, have rollback strategies, and communicate extensively with your team and customers.
But make it through to the other side, and you'll have infrastructure that grows right along with you.
When to Make the Jump
Startups attempting to solve existing problems in novel ways exist for a reason. Occasionally they’re right and become “the way” of doing things. More often, they may be directionally correct but not have the resources, capital or desire to continue.
While we were burned a few times, we likely would have continued trying new products because honestly, it’s fun!
For us, at our current stage, it was the right transition. We have scaling users, some form of product market fit and uptime expectations. A startup-first approach served us incredibly well when we needed to move fast and prove we were actually solving a problem.
Here are some signals that suggest it might be time to consider migrating:
You're spending more time managing vendor relationships than building features
Vendor limitations are constraining your product roadmap
Your operational costs are growing faster than your revenue
You need more control over performance and reliability characteristics
Looking Forward
The key is being intentional about where you accept vendor dependencies, and where you maintain direct control. Recognizing when you've hit an inflection point and having the courage to make a transition might be one of the most important (and impactful) technical decisions you make.
We’ll continue using and supporting startups as we grow our needs and support our users, but core infra will likely remain on the most stable and performant infrastructure available to us.
Loops launched publicly in 2023. Our infrastructure consolidation took place gradually over six months in 2025. We're happy to share more specific technical details about any part of this process, and definitely hit us up if you're going through something similar.
